Doctors’ Sidekick – How Do OpenEvidence Give Superheroes New Superpower?

AI is no longer a novelty to us, especially after its rapid expansion since the pandemic. While it’s undeniably powerful, it’s still evolving—and that means it can still make mistakes.
In many contexts, these mistakes might be minor or easily corrected. But in high-stakes fields like medicine, where decisions can directly affect human lives, even a small error can lead to catastrophic outcomes. This is why building trust is essential for companies seeking to integrate AI into the medical field.
“If you look at AI right now, there is no question as to how powerful AI can be. The big question is: can you trust it?” said Pat Grady, Sequoia Capital partner.
In a world where AI tools are rapidly reshaping healthcare, not every company treats trust the same way. Some see it as a bonus—something to build later, once the tech is working. But not OpenEvidence. They understood from day one that in medicine, trust isn’t optional. It can’t be an afterthought or a marketing slogan. For them, trust is the very foundation of their work.
Trust is undeniably important—but it’s just one part of a much bigger blueprint that has propelled OpenEvidence into unicorn status. Their rise wasn’t accidental, and it wasn’t built on hype. Before uncovering the secret sauce behind their success, it’s worth going all the way back—to the very beginning—to understand how the company was born, the problems they set out to solve, and the mindset that shaped their journey. Because to truly grasp why OpenEvidence is different, you have to see where it all started.
From Kensho to OpenEvidence – Pioneers in LLMs
Today, AI and LLMs have become household terms thanks to their explosive growth in recent years—but long before this boom, visionaries like Daniel Nadler, co-founder of OpenEvidence, were already pioneering the future of intelligent systems.
In 2013, while still a PhD student at Harvard, Daniel Nadler founded Kensho, an AI company that pioneered the use of natural language processing and machine learning in financial services. Kensho allowed users to ask complex financial and geopolitical questions in plain English and receive real-time, data-backed answers—transforming how analysts and institutions processed market intelligence.
Its advanced, domain-specific technology quickly attracted major financial players like Goldman Sachs and eventually led to a landmark acquisition by S&P Global in 2018 for $550 million.
With his first company, Kensho, he was primarily focused on ensuring the business survived, which is a common mindset for first-time founders trying to prove themselves. After achieving success, his focus shifted toward creating something with deep and lasting impact.
“With your first company you’re you’re just trying to succeed, you’re you’re trying to make sure it doesn’t fail. I think then after that you start to think about founding something that has a tremendous impact and that’s what led me to to healthcare and and to this problem,” he reflected.
That shift led him to healthcare, a field he was also personally drawn to because of family experiences. He views healthcare as one of the most urgent and human-centered problems of our time. Unlike many AI applications that seem like solutions in search of a problem, healthcare is a real problem in desperate need of a solution.
According to him,, The United States is facing a projected shortage of 100,000 doctors by the end of the decade, with only about one million active doctors serving 340 million people. At the same time, medical knowledge is growing rapidly, with two new medical papers published every minute. It has become nearly impossible for doctors to keep up.
Nadler believes that when doctors struggle, patients suffer even more, and that insight became the foundation for creating OpenEvidence.
Tackling the Toughest Challenges – How Many Pain Points Can OpenEvidence Solve?

So OpenEvidence is an AI co-pilot for doctors that helps them make high-stakes clinical decisions at the point of care. It is an AI-powered medical information platform that provides accurate medical information to health care professionals. One memarkble thing is It’s used by over a quarter of U.S. doctors today, this is because OpenEvidence can really solve the problems of doctors, starting with the overwhelming and ever-accelerating growth of medical knowledge, and the impossibility for doctors to keep up with it all.
Empowers Doctors in the Age of Information Overload
Daniel Nadler believes that the best technology starts with solving a real, urgent problem—not just chasing trends. In healthcare, one of the most overlooked yet critical challenges doctors face is the overwhelming explosion of medical knowledge.
Since 1950, the pace of medical knowledge growth has accelerated dramatically—from doubling every 50 years to now doubling every 5 years, according to OpenEvidence’s internal study. Back then, a doctor could rely on their medical school education to remain relevant for most of their career. Today, however, by the time a doctor completes residency or fellowship, half of what they learned may already be outdated.
This is due to the sheer volume of new research—two new medical papers are published every minute, around the clock. While not all studies are equally important, even focusing only on high-impact, clinically relevant research reveals a staggering rate of change. This rapid evolution makes it nearly impossible for doctors to stay current on their own.
“Two new medical papers are published every minute, 24 hours a day, 7 days a week. A study published in Nature once claimed that medical knowledge doubles every 73 days. That methodology might be a bit aggressive, so at OpenEvidence we conducted our own internal study and arrived at a more conservative—but still staggering—estimate: medical knowledge doubles every 5 years. That’s still incredibly fast,” he explained.

In the past, doctors could rely on what they learned in medical school for most of their careers. But today, medical knowledge changes so quickly that their training becomes outdated within just a few years. For example, a dermatologist treating a patient with psoriasis might usually know what medicine to use—but if that patient also has multiple sclerosis (MS), the choice becomes tricky.
Some drugs can make MS worse, while newer, safer options only became available recently. Since these newer treatments weren’t around when many doctors were in school, they may not know about them. And with so much new research being published all the time, it’s just not realistic to expect doctors to keep up with everything on their own.
This is where OpenEvidence comes in—it helps doctors answer highly specific, nuanced clinical questions that traditional tools like Google or PubMed can’t handle effectively. These complex, edge-case scenarios are common in medicine, and solving them not only improves clinical accuracy but also enhances patient outcomes and reduces the risk of harmful errors.
And it’s working—doctors repeatedly tell Nadler that they use OpenEvidence for cases they only encounter once or twice in their entire careers. In a field where nearly every patient is an exception, OpenEvidence gives doctors what they need most: trustworthy, precise answers when it matters most.
“Doctors tell us this all the time. They say things like, ‘I used OpenEvidence for a case I might only see once or twice in my career.’ And then they say it again, for another case. And again, and again. That’s when you realize how long the tail really is. If most uses of OpenEvidence are for cases doctors only see once or twice in a career, then it captures exactly what the product is doing—it’s running search, discovery, and clinical knowledge retrieval across a long-tail domain that, for all practical purposes, might as well be infinite.” Daniel proudly recalled.
Cost Saving!
According to Pat Grady, partner at Sequoia Capital, OpenEvidence plays a critical role in reducing healthcare costs by improving clinical decision-making at the point of care. One of the most overlooked drivers of healthcare spending is the cycle of patients receiving suboptimal treatment, experiencing complications or relapses, and re-entering the system for additional care. This not only burdens patients but also generates enormous downstream costs for hospitals, insurers, and the broader healthcare system.
OpenEvidence addresses this by equipping doctors with real-time, evidence-based insights tailored to complex, often rare clinical scenarios—cases where traditional tools like Google or PubMed fall short.
By helping physicians make more accurate, personalized decisions from the start, OpenEvidence reduces the likelihood of misdiagnosis, ineffective treatments, and avoidable readmissions. This leads to fewer repeat visits, shorter hospital stays, and less reliance on costly interventions, all of which contribute to significant cost savings.
Grady also said that improving patient outcomes and reducing waste are not separate goals—they’re deeply connected. When doctors have better tools, patients get better faster and stay healthier longer, which ultimately lowers the total cost of care across the system.
“One of the reasons there’s so much waste — or at least cost — in the healthcare system is because patients are treated, they get sick again, and they have to go back into the system. That’s an enormous driver of cost. And if you can improve patient outcomes by helping doctors make clinical decisions at the point of care using the latest and most up-to-date information, then that’s going to reduce the rate at which people get sick again. It’s going to reduce the rate at which people have to go back into the healthcare system,” he articulated.
OpenEvidence is Here to Help, Not to Replace Doctors!

While many industries are bracing for AI to take over jobs, healthcare tells a very different story. Daniel Nadler, co-founder of OpenEvidence, sees the reality firsthand: doctors aren’t worried about being replaced by AI—they’re overwhelmed by a system on the brink.
With a projected shortage of 100,000 physicians by the end of the decade, the U.S. healthcare system is facing a national emergency. Doctors are overworked, stretched thin, and struggling to keep up with a tidal wave of new medical knowledge. In that environment, OpenEvidence isn’t a threat—it’s a lifeline.
The platform was never built to replace doctors. It was built to serve them—to be the co-pilot they desperately need at the point of care.
OpenEvidence lightens the burden on doctors by equipping them with fast, reliable answers grounded in trusted, peer-reviewed medical evidence. Rather than replacing physicians, it enhances their ability to do what they do best: deliver thoughtful, high-quality care to their patients.
“Doctors have no concern about being automated. Their concern is: how do we get more doctors in the workforce, and how do we make the life of being a doctor easier to deliver better care for patients,” said Daniel Nadler.
No Hallucinations!
Daniel points out that in some industries—like image generation or even certain areas of finance—what’s traditionally labeled as “hallucination” in AI isn’t just tolerable, but actually desirable. But in medicine, hallucination is never a feature, as strongly stated by him.
Unlike many AI tools that may generate uncertain or misleading answers, OpenEvidence is designed specifically for healthcare and built to meet the high standards doctors require. If it doesn’t know the answer, it simply says so—avoiding the risk of hallucinations or false confidence.
This makes it a tool that clinicians can rely on when making critical decisions, especially in high-stakes situations. Its focus on accuracy, transparency, and safety is what truly sets it apart in the world of AI for medicine. This is how they has become a trusted colleague to doctors.
“For us, trust can’t be a feature, it has to be the core of what we do” the co-founder of OpenEvidence stated.
To achieve this kind of trust, OpenEvidence had to take the opposite path: training smaller, highly specialized models on only peer-reviewed, trusted medical literature, and excluding the open internet entirely.
OpenEvidence not only provides accurate, evidence-based answers, but also shows doctors exactly where that information comes from—down to the original peer-reviewed study. This transparency builds trust and has created a mutually beneficial relationship with medical publishers, as the platform drives tens of millions of visits to journal articles that doctors might not have found otherwise.
As a result, medical societies began reaching out to OpenEvidence, asking for their guidelines to be indexed on the platform. They recognized that being included meant more exposure and more traffic from clinicians actively seeking high-quality, evidence-based guidance. What started as a tool for accuracy evolved into a virtuous cycle—one where better information access led to better decisions, which in turn reinforced the value of the platform for all stakeholders.
“So, you get accuracy. You get a symbiotic and mutually beneficial relationship with medical journal owners. But critically, you get the right information back to the doctor using OpenEvidence—who then will make the better decision as a result of having better information for their patient at the point of care,” Daniel said.
How Did OpenEvidence Build Such a Product?

Trust in Medical AI Starts With the Quality of the Data
Daniel Nadler wants to make one thing unmistakably clear: trust in medical AI starts with the quality of the data. Unlike other AI tools that scrape the public internet—where well-meaning but unqualified bloggers might shape clinical suggestions—OpenEvidence draws a hard line.
Its models are never trained on random web content, social media, or health blogs. Instead, they’re built solely on peer-reviewed medical literature from top-tier sources like the New England Journal of Medicine (NEJM), FDA, and CDC.
In fact, Nadler points out that OpenEvidence is the only AI system with full-text training access to NEJM—something even the most well-funded tech giants failed to secure.
“To the best of my knowledge we’re the only AI company that they’ve done this with without getting into the specifics,” he said.
And that exclusivity didn’t come from aggressive corporate lobbying or big checks—it came from OpenEvidence’s grassroots growth. Senior editors at NEJM were already avid users of the tool and saw firsthand how it elevated clinical decision-making. They approached OpenEvidence to forge a partnership—not the other way around.
This deliberate design philosophy extended into the very architecture of OpenEvidence. Rather than chasing massive, general-purpose models trained on everything under the sun, Nadler and his elite team of Harvard and MIT scientists focused on small, specialized models—trained rigorously on domain-specific data. They approached the challenge academically and technically, publishing research like “Do We Still Need Clinical Language Models?”, which won Best Paper in Machine Learning in 2023.
In fact, without getting into the specifics of it, some of these really well-funded AI companies threw enormous amounts of money at them—and they still said no. If they were a private company, they probably would have said yes. But they’re a nonprofit, so they said no because the Massachusetts Medical Society cared more about the sanctity and pristineness of their mission as a nonprofit than they did about just trying to score some sort of quick commercial contract.
In the case of OpenEvidence—again, it was beautiful. The very senior people there were users. And then this sort of circles back to what we talked about right at the start: had we waited, had we taken a top-down approach, had we taken an enterprise SaaS approach and been in waiting mode for meeting number 17 with the hospital system—and no one was using it—well, if no one was using it, that would include no one at the New England Journal of Medicine using it. Which would have meant that they wouldn’t have fallen in love with it, which meant that we would have never had an opportunity to strike a content partnership with them. That, in turn, made the whole thing that much better and more awesome to the people using it.
So you get into vicious cycles versus virtuous cycles. In our case, the whole thing was a cycle: we put it out there, people downloaded it for free. Some of those people included very senior people at the New England Journal of Medicine. They started using it. They fell in love with it. They reached out to us. We did this deal. And now the thing is 10,000 times better because it is trained on the full text of the New England Journal of Medicine.
No AI today in the market—I can tell you with certainty—no AI today in the market is training on the full text of the New England Journal of Medicine other than OpenEvidence.
Precision Over Scale
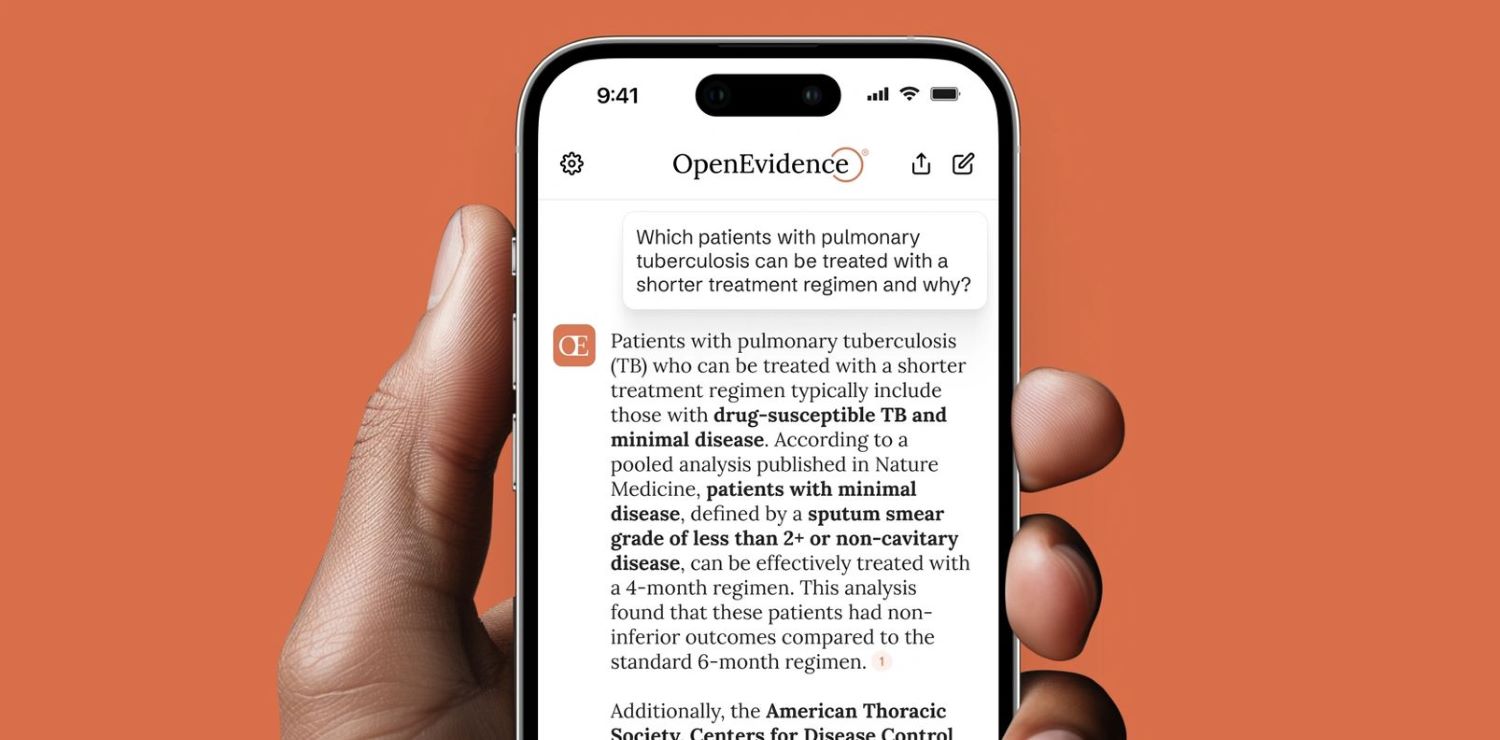
When OpenEvidence set out to tackle the challenge of clinical decision-making with AI, they didn’t follow the prevailing wisdom of scaling bigger and faster. Instead, they took a bold, unconventional route—a rigorously academic and highly specialized approach rooted in domain expertise and precision.
Co-founder Daniel Nadler and his team assembled a powerhouse group of scientists from the world’s leading NLP labs—names like Harvard and MIT. These weren’t just engineers building another AI app—they were researchers deeply immersed in the frontier of machine learning, language models, and biomedical reasoning.
While much of the AI world raced to build ever-larger general-purpose models, OpenEvidence leaned into a counterintuitive insight: smaller, specialized models trained on high-quality, in-domain data consistently outperform larger models in high-stakes domains like medicine. Their models didn’t try to do everything—they were laser-focused on doing one thing extremely well.
This wasn’t a guess. They published original research, including the award-winning 2023 paper “Do We Still Need Clinical Language Models?”, which became the first to demonstrate that tightly scoped, deeply trained models beat the giants in accuracy and reliability for clinical tasks.
“That was our approach. It was very technical, very academic, and very scientific—because accuracy mattered that much in medicine,” he stated.
Hire Elite People
Daniel doesn’t mince words when it comes to what makes great teams: “A-players want to work with A-players.” To him, elite talent attracts elite talent—not out of ego, but out of a deep desire to test themselves, to stretch the limits of their own abilities. Whether it’s Navy SEALs or AI labs, the best don’t just want to succeed—they want to see how they measure up against others operating at the peak of human potential.
That’s why, when he built OpenEvidence, he assembled a founding team of high-IQ, high-neuroplasticity individuals—people with an uncanny ability to absorb, adapt, and respond to rapidly changing conditions, just like the great generals of history.
“I just want people with really high IQs. I don’t care about anything else,” he said.
Daniel built his early team with people from places like Harvard and MIT not for prestige, but because he’d learned at Kensho that small teams of fast-learning, high-IQ individuals solve hard problems far better than larger, average ones. It wasn’t about the schools—it was about capability and adaptability.
He explained, “And so if you think about the people—the first four or five people—Zachary Ziegler, Jonas Wolf, Evan Hernandez, Eric Lehman, Micah Smith—that came together as senior people on my team initially… yeah. Every one of them, if I have to sort of classify this way, came from a PhD program at Harvard or MIT,”
He added, “But that’s not because I’m like, ‘I’m only going to recruit from Harvard and MIT.’ It was because I had the Kensho experience, and I learned from that experience that if you bring very high IQ people, with very high velocity of learning, to bear on a very difficult problem—they make more progress, far more quickly, than a team 100 times that size that’s a more normal team.
No Fancy Marketing Campaign!

Doctors, despite operating in a highly specialized and regulated field, are still consumers—and they behave like consumers, as stated by Daniel Nadler. While many startups fail in healthcare by trying to go top-down—navigating complex hospital bureaucracies and endless committee meetings—Nadler and his team took a radically different path.
Drawing from his experience building Kensho, he recognized the inefficiency of institutional gatekeeping and instead focused on bottom-up adoption. The strategy was simple but powerful: make something doctors genuinely love and make it easily accessible. No fancy marketing, no enterprise sales gauntlet—just a truly valuable product, offered for free in the App Store.
That consumer-first thinking paid off. Word spread organically from one doctor to another, and usage skyrocketed. In just a year, OpenEvidence went from a few early adopters to being used by up to a quarter of active physicians in the United States.
“You make something awesome, you put it out on the App Store for free, and it turns out that without fancy marketing campaigns or large marketing budgets, all of our growth is word-of-mouth—doctor to doctor to doctor. People start using it. People discover it. And when they start using it, if it’s really awesome, they’ll tell other people about it,” said OpenEvidence’s co-founder.







